什麼是BERT? 最近研究自然語言處理(NLP)在藝術創作上可以發揮什麼用途,不能不知道Google AI Language在2019年發表的 Pre-training of Deep Bidirectional Transformers for Language Understanding這一篇論文。
網路上探討BERT跟數學公式解釋的文章很多,可是要怎麼變成簡單好用的互動藝術創作? 畢竟要會用才意義。以下我們先看懂BERT原理是什麼,並白話一點介紹給各位同學理解BERT有趣的地方在哪!
BERT白話來說,就是通過引入雙向上下文的預訓練(Pre-training)和微調(Fine-Tuning)方法,他徹底改變了自然語言處理領域。與之前的模型(如word2vec或ELMo)不同,word2vec是無上下文的,而ELMo僅部分具備上下文感知能力,BERT則使用雙向Transformer架構,能夠同時考慮一個詞的左右兩側上下文,從而更全面地理解語言。
這篇論文提出了BERT的兩個主要階段:
- 預訓練(Pre-training):在大量未標記文本上進行預訓練,學習通用的語言表示。
- 微調(Fine-tuning):在特定下游任務上使用標記數據對預訓練模型進行微調。
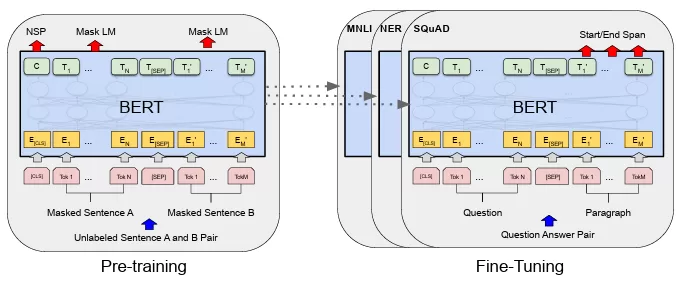
1. 預訓練(圖片左側)
我們先來看大量未標記文本上預訓練。
他的任務:
- 遮罩語言模型(Masked Language Model, MLM):
- BERT會隨機遮罩句子中15%的詞(圖中以[MASK]表示)。
- 模型根據詞的左右上下文來預測這些被遮罩的詞。
- 例如,圖中展示了“未標記的句子A和B對”(Unlabeled Sentence A and B Pair),其中某些詞(如T'[SEP])被遮罩,模型需要預測這些詞。
- 為了避免過擬合,BERT採用了以下策略:
- 80%的情況下,被遮罩的詞會被替換為[MASK]。
- 10%的情況下,替換為一個隨機詞。
- 10%的情況下,保持不變。
- 這一任務使BERT能夠學習深層的雙向表示,這與單向模型(如GPT,只看左側上下文)不同。
- 下一句預測(Next Sentence Prediction, NSP):
- BERT接收一對句子(句子A和句子B)作為輸入。
- 模型預測句子B是否是句子A在原始文本中的下一句(50%的情況下是,50%的情況下是隨機選擇的句子)。
- 圖中通過[CLS]標記(位於輸入的開頭)來輸出NSP的分類預測。
- 這一任務幫助BERT理解句子之間的關係,這對於問答系統和自然語言推理等任務非常重要。
從輸入那一側可以表示:
- 輸入由句子A和B的標記(T1, T2, …, TN)組成,兩句之間用特殊標記[SEP]分隔。
- 每個標記由三種嵌入(embedding)組成:
- 標記嵌入(Token Embedding)(E1, E2, …, EN):表示詞本身。
- 段落嵌入(Segment Embedding)(EA, EB):標示該標記屬於句子A還是句子B。
- 位置嵌入(Position Embedding):編碼標記在序列中的位置。
- 這些嵌入被輸入到BERT模型中,BERT由多層Transformer組成(圖中未顯示,但隱含在模型中)。
然後在輸出那一側:
- 預訓練階段的輸出包括:
- 對遮罩詞的預測(通過MLM)。
- 對NSP的分類預測(通過[CLS]標記)。
2. 微調(圖片右側)
微調是指特定下游任務上使用標記數據對預訓練的BERT模型進行微調。
他的任務:
- 圖中展示了幾個下游任務:
- MNLI(多類型自然語言推理):預測前提(premise)與假設(hypothesis)之間的關係(蘊含、矛盾或中立)。
- NER(命名實體識別):識別文本中的實體(如人名、組織名)。
- SQuAD(斯坦福問答數據集):根據給定的段落回答問題,預測答案的起始和結束位置(圖中標記為“Start/End Span”)。
- 每個任務的輸入格式略有不同:
- 對於MNLI/NER,輸入是一個單一序列或一對序列(如前提和假設)。
- 對於SQuAD,輸入是一個問題和一個段落,模型預測答案的起始和結束位置。
微調過程:
- 預訓練的BERT模型通過在頂部添加一個任務特定的輸出層進行微調。
- 例如:
- 在SQuAD中,模型輸出答案的起始和結束位置。
- 在MNLI中,[CLS]標記的表示用於分類(蘊含、矛盾或中立)。
- 整個模型(BERT + 任務特定層)在標記數據集上進行端到端的微調。
輸入表示:
- 與預訓練類似,輸入由標記(T1, T2, …, TN)組成,並使用段落嵌入來區分問題和段落(對於SQuAD)或前提和假設(對於MNLI)。
輸出:
- 輸出取決於任務:
- 對於SQuAD,模型預測答案的起始和結束位置。
- 對於MNLI,輸出分類標籤。
- 對於NER,為每個標記分配一個實體標籤。
介紹完上面的技術細節後,白話一點舉幾個例子:
- 故事創作應用
- 生成出藝術品的描述應用
- 藝術評論
- 文本生成圖
- 文本生成音樂
- 對話式藝術創作
- 藝術風格(文學風格)模仿應用或翻譯
- 情感分析與生成
可以想像到BERT主要的藝術創作應用在文字方面的生成、創作、模仿甚至分析…等,如果實際上要來應用,該怎麼開始呢? 以下用python程式碼帶各位同學手把手來完成一個簡單的BERT的藝術創作應用~
[程式碼下載]
[BERT動手玩]